

Machine Learning em saúde não é uma “caixa preta” na maioria dos casos. Os algoritmos mais usados com dados estruturados são bem documentados e permitem interpretar a contribuição de cada variável preditora, por exemplo, por meio de gráficos de Shapley. A característica de “caixa preta” aplica-se sobretudo a modelos complexos de Deep Learning, e não à vasta maioria das técnicas de aprendizado de máquina.
A predição na área da saúde é um ramo amplo e envolve técnicas diversas. Nos últimos anos, o uso de técnicas de Inteligência Artificial (IA), particularmente de Machine Learning, tem se tornado cada vez mais popular. Quando pesquisamos pelos termos “machine learning” e “prediction” na base de artigos médicos PubMed, torna-se evidente a recente e crescente popularidade desses temas nos artigos publicados no mundo.
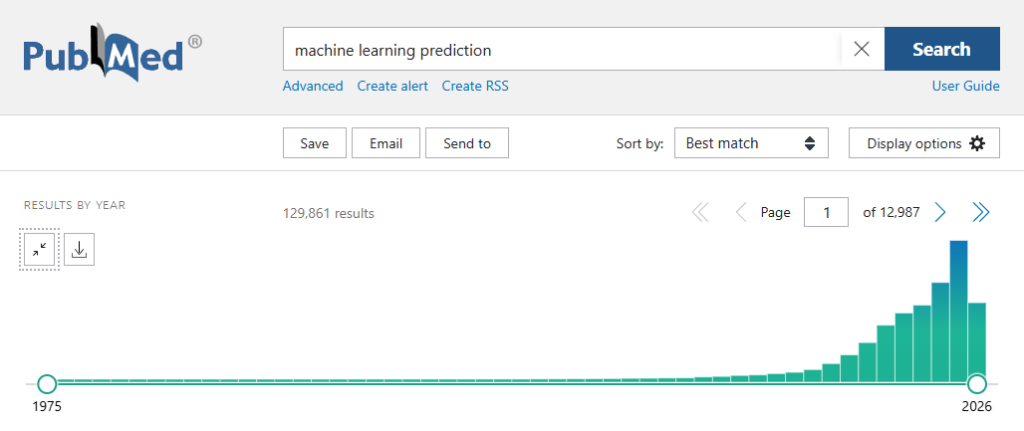
Uma preocupação igualmente crescente, no entanto, diz respeito à interpretação dos resultados dos algoritmos preditivos em saúde. Dependendo do tipo de algoritmo utilizado, pode ser difícil explicar em termos simples a lógica que levou a determinado resultado preditivo.
Alguns têm atribuído a qualidade de “caixa preta” aos algoritmos de machine learning. Cabe a ressalva, no entanto, de que o adjetivo não é apropriado na maioria dos casos. Vejamos por quê.
Machine Learning em saúde não envolve apenas Deep Learning
Deep Learning é um ramo do machine learning particularmente útil em problemas que envolvem dados não-estruturados, como análise de imagens médicas e processamento de linguagem natural. Nesses modelos, formados por “redes neurais profundas” que mimetizam o funcionamento dos neurônios cerebrais, as etapas de processamento são numerosas e complexas. Por isso, fica dificultada a plena descrição das variáveis preditoras (features) que interferem nos resultados.
Trabalhos têm sido feitos analisando essa questão. A tendência é que se aperfeiçoem os métodos de descrição dos modelos. Além disso, espera-se que se amplie o conhecimento geral dos princípios da IA aplicada à saúde, mitigando ao menos parcialmente a incompreensão que pode permear os consumidores dos modelos preditivos.
Machine Learning aplicado a dados estruturados em saúde
Aqui na Lean Saúde trabalhamos sobretudo com algoritmos de IA utilizando dados estruturados, isto é, dados tabulares relacionados à clínica de pacientes, dados demográficos, informações de sinistralidades, entre outros.
Os algoritmos mais utilizados nesse ramo da IA facilitam a interpretação dos modelos e das variáveis preditoras (features). Por exemplo, por meio de gráficos de Shapley, que permitem visualizar a contribuição de cada feature para determinado modelo preditivo.
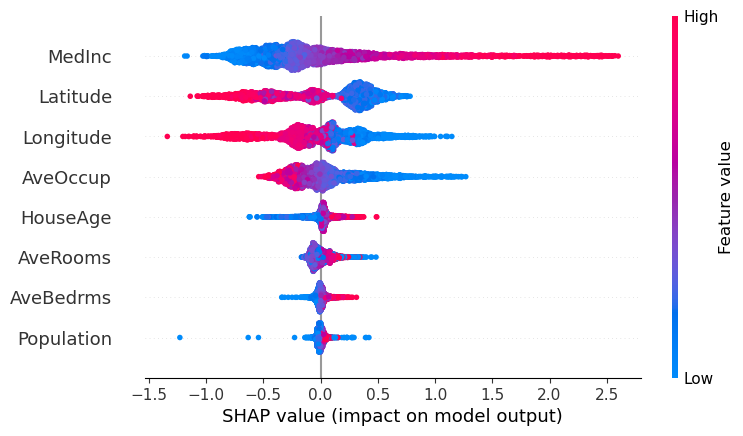
Documentação dos algoritmos de machine learning
Via de regra, os algoritmos de machine learning são bem documentados e possuem seu mecanismo de funcionamento (código-fonte) disponível para consulta e estudo. Por isso, não é plenamente correto atribuir a característica de “caixa preta” à vasta maioria dos algoritmos, uma vez que sua utilização se baseia numa lógica previsível e documentada.
Certo é que os algoritmos de machine learning fornecem uma modelagem computacional complexa. Não por acaso, têm apresentado uma acurácia preditiva superior à maioria das técnicas tradicionais, como a regressão linear. Em problemas particularmente complexos, por exemplo na área de saúde pública, medicina e economia da saúde, há múltiplas variáveis que se relacionam de modo complexo. Nesse caso, modelagens muito simples podem não ser ideais.
As técnicas tradicionalmente usadas na estatística, como a regressão acima mencionada, têm sua utilidade e seus prós e contras. Não à toa, fazem parte da rotina de predição e da inferência estatística de longa data. Mesmo em situações específicas, podem apresentar desempenho superior a algoritmos de machine learning, conforme as comparações feitas pelos cientistas de dados.
Uma vantagem delas é justamente a facilidade de sua interpretação, atribuindo pesos às variáveis preditoras que se somam num modelo linear, por exemplo. No entanto, há perda de acurácia preditiva nessa modelagem matemática de problemas complexos. Além disso, pode-se induzir a erros de interpretação pelo público leigo, com frequência creditando uma interpretação biológica pareada de modo exato ao modelo matemático simplificado.
Discernimento e boa técnica
A chave para adotar de maneira responsável uma ou outra técnica preditiva passa por alguns princípios:
- Aprimorar continuamente os esforços de divulgação da IA junto às pessoas que utilizarão os modelos preditivos;
- Aprimorar continuamente as técnicas de análise das variáveis preditoras, sobretudo nos algoritmos de deep learning, para que se identifiquem potenciais vieses dos modelos;
- Comparar os prós e contras dos modelos tradicionais e dos modelos de machine learning utilizando métricas objetivas, sem ideias pré-concebidas ou achismos;
- Aprimorar os métodos de interpretação dos mecanismos dos algoritmos de machine learning, para ampliar sua “explicabilidade”, um ramo de pesquisa chamado de “XAI – Explainable Artificial Intelligence”;
- Utilizar boas práticas no processamento de big data e na modelagem de modelos preditivos, atentando-se a todas as etapas de pré-processamento e a todas as validações dos modelos.
Em resumo, a maioria dos algoritmos de machine learning em saúde é interpretável e documentada, e a alcunha de “caixa preta” reflete mais a complexidade de certos modelos de Deep Learning do que uma limitação real da área. Para aplicações que dependem de antecipar eventos clínicos e estratificar risco, soluções de análise preditiva em saúde combinam acurácia e explicabilidade. Para aprofundar o tema, vale acompanhar os conteúdos do blog da Lean Saúde.





